Goal-Conditioned End-to-End Visuomotor Control
for Versatile Skill Primitives
2021 IEEE International Conference on Robotics and Automation (ICRA)
Oxford A2I, VGG
Oxford A2I, DRS
Oxford VGG
Oxford A2I
Abstract
Visuomotor control (VMC) is an effective means of achieving basic manipulation tasks such as pushing or pick-and-place from raw images. Conditioning VMC on desired goal states is a promising way of achieving versatile skill primitives. However, common conditioning schemes either rely on task-specific fine tuning - e.g. using one-shot imitation learning (IL) - or on sampling approaches using a forward model of scene dynamics i.e. model-predictive control (MPC), leaving deployability and planning horizon severely limited. In this paper we propose a conditioning scheme which avoids these pitfalls by learning the controller and its conditioning in an end-to-end manner. Our model predicts complex action sequences based directly on a dynamic image representation of the robot motion and the distance to a given target observation. In contrast to related works, this enables our approach to efficiently perform complex manipulation tasks from raw image observations without predefined control primitives or test time demonstrations. We report significant improvements in task success over representative MPC and IL baselines. We also demonstrate our model's generalisation capabilities in challenging, unseen tasks featuring visual noise, cluttered scenes and unseen object geometries.
Motivation
Learn re-usable, versatile skill primitives and apply them to new contexts instead of learning every task from scratch.
Idea
Use a single target image to goal-condition a visuomotor policy on a new task without finetuning the controller.

Initial observation

Target image
Model
Leverage dynamic images to introduce an inductive bias about object shapes and encode motion dynamics.
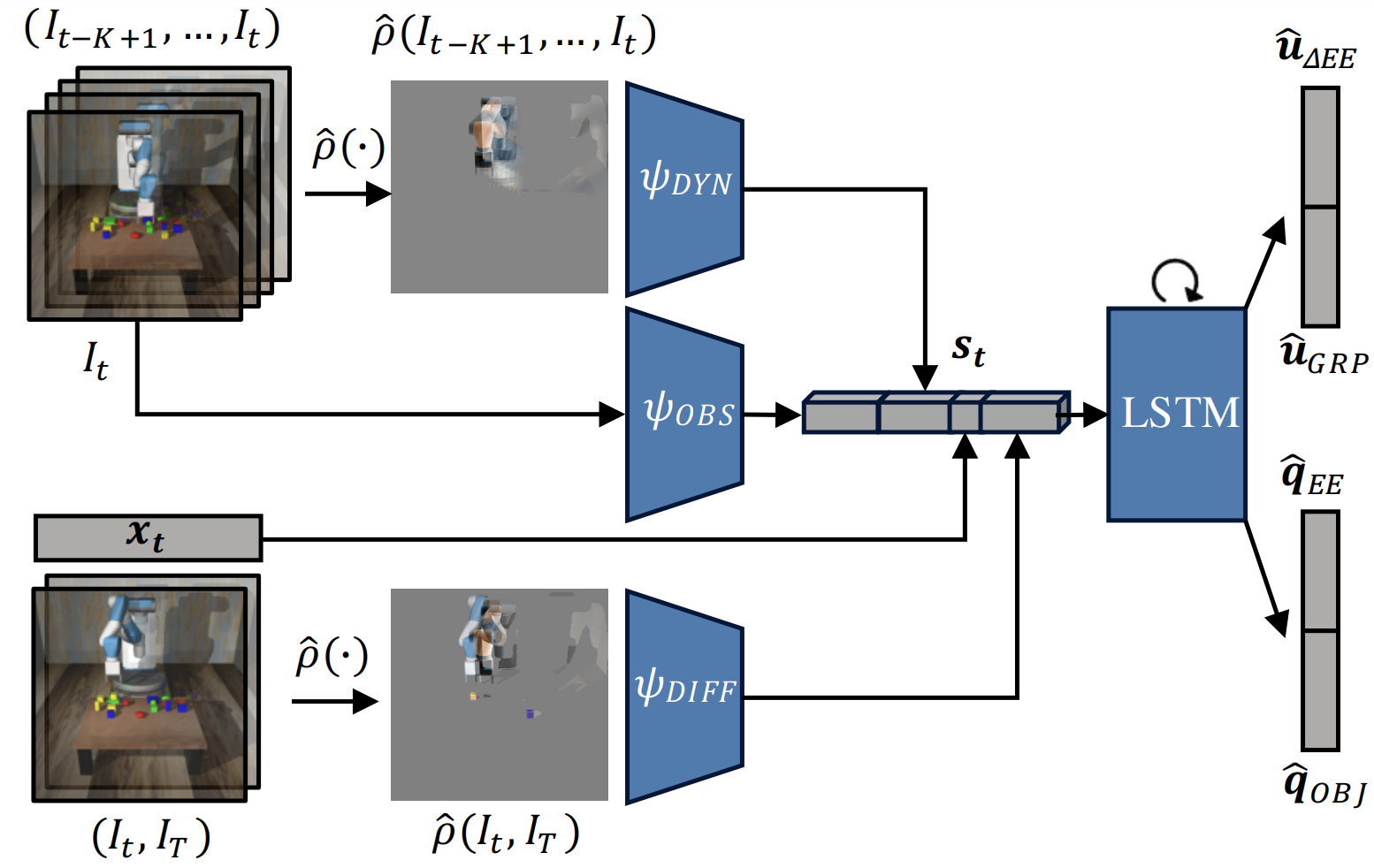
Dataset
8 hours of scripted task demonstrations per skill in simulation
Pushing
Pick-and-place
Side-by-side comparison

Target image
VFS
TecNets
GEECO (ours)
Pushing

Target image
VFS
TecNets
GEECO (ours)
Pick-and-place
Qualitative behaviour
GEECO can regrasp without encountering episodes with regrasps in the training data.

Target image
RGB stream
Target difference
Motion buffer
GEECO struggles with depth and motion ambiguities.

Target image
RGB stream
Target difference
Motion buffer
Generalisation to new scenarios
GEECO performs a pick-and-place task under heavy clutter.

Target image
RGB stream
Target difference
Motion buffer
GEECO is not distracted by colour distortions in the background.

Target image
RGB stream
Target difference
Motion buffer
GEECO places a novel nut on a small cone.

Target image
RGB stream
Target difference
Motion buffer
GEECO puts a small ball into a cup.

Target image
RGB stream
Target difference
Motion buffer
Citation
@inproceedings{groth2021goal,
title={Goal-conditioned end-to-end visuomotor control for versatile skill primitives},
author={Groth, Oliver and Hung, Chia-Man and Vedaldi, Andrea and Posner, Ingmar},
booktitle={2021 IEEE International Conference on Robotics and Automation (ICRA)},
pages={1319--1325},
year={2021},
organization={IEEE}
}Acknowledgement
Oliver Groth is funded by the European Research Council under grant ERC 638009-IDIU. Chia-Man Hung is funded by the Clarendon Fund and receives a Keble College Sloane Robinson Scholarship at the University of Oxford. This work is also supported by an EPSRC Programme Grant [EP/M019918/1]. The authors acknowledge the use of Hartree Centre resources in this work. The STFC Hartree Centre is a research collaboratory in association with IBM providing High Performance Computing platforms funded by the UK’s investment in e-Infrastructure. The authors also acknowledge the use of the University of Oxford Advanced Research Computing (ARC) facility in carrying out this work (http://dx.doi.org/10.5281/zenodo.22558). Special thanks goes to Frederik Ebert for his helpful advise on adjusting Visual Foresight to our scenarios and to Ștefan Săftescu for lending a hand in managing experiments on the compute clusters. Lastly, we would also like to thank our dear colleagues Sudhanshu Kasewa, Sebastien Ehrhardt and Olivia Wiles for proofreading and their helpful suggestions and discussions on this draft.